
Suchmaschine
Eine Suchmaschine ist ein Programm zur Recherche von Dokumenten, die in einem Computer oder einem Computernetzwerk wie z. B. dem World Wide Web gespeichert sind. Nach Eingabe eines Suchbegriffs liefert eine Suchmaschine eine Liste von Verweisen auf möglicherweise relevante Dokumente, meist dargestellt mit Titel und einem kurzen Auszug des jeweiligen Dokuments. Dabei können verschiedene Suchverfahren Anwendung finden.
Die wesentlichen Bestandteile bzw. Aufgabenbereiche einer Suchmaschine sind
- Erstellung und Pflege eines Indexes (Datenstruktur mit Informationen über Dokumente),
- Verarbeiten von Suchanfragen (Finden und Ordnen von Ergebnissen) sowie
- Aufbereitung der Ergebnisse in einer möglichst sinnvollen Form.
In der Regel erfolgt die Datenbeschaffung automatisch, im WWW durch Webcrawler, auf einem einzelnen Computer durch regelmäßiges Einlesen aller Dateien in vom Benutzer spezifizierten Verzeichnissen im lokalen Dateisystem. Wird die Datenbeschaffung manuell mittels Anmeldung oder durch Lektoren vorgenommen, handelt es sich nicht um eine Suchmaschine sondern um einen Katalog (auch Verzeichnis genannt). In solchen Verzeichnissen wie beispielsweise Yahoo! und dem Open Directory Project sind die Dokumente hierarchisch in einem Inhaltsverzeichnis nach Themen organisiert.
Metasuchmaschinen schicken Suchanfragen parallel an mehrere normale Suchmaschinen und kombinieren die Einzelergebnisse zu einer Ergebnisseite. Als Vorteil ist die größere (da kombinierte) zugrundeliegende Datenmenge zu nennen. Ein Nachteil ist die lange Dauer der Anfragebearbeitung. Außerdem ist das Ranking durch reine Mehrheitsfindung (welche Seite taucht in den meisten verwendeten Suchmaschinen auf?) von fragwürdigem Wert. Metasuchmaschinen sind vor allem bei selten vorkommenden Suchbegriffen von Vorteil.
Als Desktop-Suchmaschine werden neuerdings Programme bezeichnet, welche den lokalen Datenbestand eines einzelnen Computers durchsuchbar machen.
So genannte Echtzeit-Suchmaschinen starten den Indexierungsvorgang erst nach einer Anfrage. So sind die gefundenen Seiten zwar stets aktuell, die Qualität der Ergebnisse ist aber aufgrund der fehlenden breiten Datenbasis insbesondere bei weniger gängigen Suchbegriffen schlecht.
Ranking
Die Darstellung der Suchergebnisse geschieht sortiert nach Relevanz (Ranking), wofür jede Suchmaschine ihre eigenen, meist geheim gehaltenen Kriterien heranzieht. Dazu gehören:
- Häufigkeit und Stellung der Suchbegriffe im jeweiligen gefundenen Dokument.
- Einstufung und Anzahl der zitierten Dokumente.
- Häufigkeit von Verweisen anderer Dokumente auf das im Suchergebnis enthaltene Dokument sowie in Verweisen enthaltener Text.
- Einstufung der Qualität der verweisenden Dokumente (ein Link von einem „guten“ Dokument ist mehr wert als der Verweis von einem mittelmäßigen Dokument).
Größere Bekanntheit erlangt hat PageRank, eine Komponente des Ranking-Algorithmus' der erfolgreichen Suchmaschine Google.
Manche Suchmaschinen sortieren Suchergebnisse nicht nur nach Relevanz für die Suchanfrage, sondern lassen gegen Bezahlung auch Einflussnahme auf ihre Ausgabe zu. In den letzten Jahren hat sich allerdings bei den großen Anbietern eine Trennung zwischen Suchergebnissen und daneben eingeblendeter zur Anfrage passender Werbung durchgesetzt.
Geschichte
Archie kann als ältester Vorfahre der heute allseits bekannten Suchmaschinen und Webverzeichnisse angesehen werden.
Der erste Vorläufer der heutigen Suchmaschinen war eine im Jahr 1991 an der University of Minnesota maßgeblich von Paul Lidner und Mark P. McCahill entwickelte Software namens Gopher. Sie wurde als Campuswide Information System (CWIS) zur Vernetzung der dortigen Informationsserver entwickelt und basiert auf dem Client/Server-Modell. Die Struktur von Gopher war für den damaligen Zeitpunkt richtungsweisend; alle Gopher-Seiten wurden katalogisiert und konnten vom Gopher-Sucher Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) komplett durchsucht werden. Allerdings verschwand Gopher schon einige Jahre später, vermutlich vor allem wegen der fehlenden Möglichkeit, Bilder und Grafiken einzubinden.
Mit der Freigabe des www-Standards zur kostenlosen Nutzung 1993 und einer handvoll Webseiten begann die einzigartige Erfolgsgeschichte des weltweiten Datennetzes. Der erste Such-Robot namens The Wanderer wurde im selben Jahr von einem Studenten des Massachusetts Institute of Technology (MIT) namens Mathew Gray programmiert. The Wanderer durchsuchte und katalogisierte von 1993 bis 1996 halbjährlich das zu dieser Zeit noch sehr übersichtliche Netz; im Juni 1993 wurden insgesamt 130 Webseiten gezählt. Im Oktober des gleichen Jahres wurde der Archie-Like Indexing of the Web (Aliweb) entwickelt, bei dem die Betreiber von www-Servern eine Beschreibung ihres Services in einer Datei ablegen mussten, um so ein Teil des durchsuchbaren Indexes zu werden.
Im Dezember 1993 gingen die Suchmaschinen Jumpstation, WorldWideWeb Worm und RBSE Spider ans Netz. Die beiden erstgenannten waren Robots, die Webseiten nach Titel und URL indizierten. RBSE Spider war die erste Suchmaschine, die ihre Ergebnisse in einem eigenen Ranking-System sortiert anzeigte. Keine dieser Suchmaschinen bietet heute noch seine Dienste an.
Im April 1994 ging eine weitere Suchmaschine namens WebCrawler online, die ebenfalls eine nach Ranking sortierte Trefferliste vorweisen konnte. 1995 wurde die Suchmaschine an AOL verkauft und ein Jahr später weiter an Excite. Im Mai begann die Arbeit von Michael Mauldins an der Suchmaschine Lycos, die im Juli 1994 online ging. Neben der Worthäufigkeit der Suchbegriffe innerhalb der Webseiten durchsuchte Lycos auch die Nähe der Suchbegriffe untereinander im Dokument.
Im selben Jahr riefen David Filo und Jerry Yang, beide damals Studenten des Fachbereichs Electrical Engineering an der Stanford University, eine Sammlung ihrer besten Web-Adressen in einem online verfügbaren Verzeichnisdienst ins Leben – die Geburtsstunde von Yahoo! - dem Akronym für "Yet Another Hierarchical Officious Oracle".
Das Jahr 1995 sollte eine bedeutende Trendwende für die erst kurze Geschichte der Suchmaschinen werden: In diesem Jahr wurden erstmals Suchmaschinen von kommerziellen Firmen entwickelt. Aus diesen Entwicklungen entstanden Infoseek, Architext (wurde später in Excite umbenannt) und Alta Vista. Ein Jahr später wurde Inktomi Corp. gegründet, dessen gleichnamige Suchmaschine zur Grundlage von Hotbot und anderen Suchseiten wurde. Führend in dieser Zeit war der Verzeichnisdienst von Yahoo, aber AltaVista – eine Mischung aus etwa „Blick von oben“ und dem Wortspiel (Palo) Alto-Vista – wurde zunehmend populär.
Ende 1998 veröffentlichten Larry Page und Sergey Brin ihre innovative Suchmaschinen-Ranking-Technologie mit dem Titel "The Anatomy of a Large-Scale Hypertextual Web Search Engine". Diese Arbeit stellte den Startschuss für die bisher erfolgreichste Suchmaschine der Welt dar: Google. Im September 1999 erreichte Google Beta-Status. Die geordnete Benutzeroberfläche, die Geschwindigkeit und die Relevanz der Suchergebnisse bildeten die Eckpfeiler auf dem Weg, die Computer-erfahrenen Nutzer für sich zu gewinnen. Ihnen folgten in den nächsten Jahren bis heute Scharen von neuen Internetbenutzern. Doch Google dominiert den Suchmaschinenmarkt nicht allein, durch spektakuläre Aufkäufe im Frühjahr 2003 sicherte sich Yahoo den Anschluss in diesem Marktsegment.
Seit 2004 gibt es nach einigen Firmenübernahmen nur mehr drei große (bezogen auf die Anzahl erfasster Dokumente) indexbasierte Websuchmaschinen. Neben Google sind dies Yahoo! Search und Microsofts MSN Search.
Herausforderungen
- Mehrdeutigkeit – Suchanfragen sind oft unpräzise. So kann die Suchmaschine nicht selbständig entscheiden, ob beim Begriff Laster nach einem LKW oder einer schlechten Angewohnheit gesucht werden soll. Umgekehrt sollte die Suchmaschine nicht zu stur auf dem eingegebenen Begriff bestehen. Sie sollte auch Synonyme einbeziehen, damit der Suchbegriff Rechner Linux auch Seiten findet, die statt Rechner das Wort Computer enthalten. Weiterhin wird oft Stemming verwendet, dabei werden Wörter auf ihren Grundstamm reduziert. So ist einerseits eine Abfrage nach ähnlichen Wortformen möglich (schöne Blumen findet so auch schöner Blume), außerdem wird die Anzahl der Begriffe im Index reduziert.
- Datenmenge – Das Web wächst schneller als die Suchmaschinen mit der derzeitigen Technik indexieren können. Dabei ist der den Suchmaschinen unbekannte Teil – das sogenannte Deep Web – noch gar nicht eingerechnet.
- Aktualität – Viele Webseiten werden häufig aktualisiert, was die Suchmaschinen zwingt, diese Seiten immer wieder zu besuchen. Dies ist auch notwendig, um zwischenzeitlich aus der Datenbasis entfernte Dokumente zu erkennen und nicht länger als Ergebnis anzubieten. Das regelmäßige Herunterladen der mehreren Milliarden Dokumente, die eine Suchmaschine im Index hat, stellt große Anforderungen an die Netzwerkressourcen (Traffic) des Suchmaschinenbetreibers.
- Spam – Mittels Suchmaschinen-Spamming versuchen manche Website-Betreiber, den Ranking-Algorithmus der Suchmaschinen zu überlisten, um eine bessere Platzierung für gewisse Suchanfragen zu bekommen. Sowohl den Betreibern der Suchmaschine als auch deren Kunden schadet dies, da nun nicht mehr die relevantesten Dokumente zuerst angezeigt werden.
- Technisches – Suche auf sehr großen Datenmengen so umzusetzen, dass die Verfügbarkeit hoch ist (trotz Hardware-Ausfällen und Netzengpässen) und die Antwortzeiten niedrig (obwohl oft pro Suchanfrage das Lesen und Verarbeiten mehrerer 100 MB Index-Daten erforderlich ist), stellt große Anforderungen an den Suchmaschinenbetreiber. Systeme müssen sehr redundant ausgelegt sein, zum einen auf den Computern vor Ort in einem Rechenzentrum, zum anderen sollte es mehr als ein Rechenzentrum geben, welches die komplette Suchmaschinenfunktionalität anbietet.
- Rechtliches – Suchmaschinen werden meist international betrieben und bieten somit Benutzern Ergebnisse von Servern, die in anderen Ländern stehen. Da die Gesetzgebungen der verschiedenen Länder unterschiedliche Auffassungen davon haben, welche Inhalte erlaubt sind, geraten Betreiber von Suchmaschinen oft unter Druck, gewisse Seiten von ihren Ergebnissen auszuschließen. Die deutschen Internet-Suchmaschinen wollen jugendgefährdende Seiten aus ihren Trefferlisten streichen durch Freiwillige Selbstkontrolle.
Siehe auch (Themen die noch nicht ausreichend im Artikel behandelt werden):
- Hubs und Authorities, Google-Bombe, Linkfarm, Web Impact Faktor, Information-Retrieval, Vektorraum-Retrieval, Data Mining, Semantic Web, Open Archives Initiative, Web Mining, Schnitzelmitkartoffelsalat, Nutch, Objektivität
Literatur
- Stefan Karzauninkat: Die Suchfibel Wie findet man Informationen im Internet? Klett, 2002 3. Aufl. ISBN 3-12-238106-0
Wichtige Suchmaschinen (Auswahl)
- Alltheweb (http://www.alltheweb.com/ ) - Yahoo Technologie
- AltaVista (http://www.altavista.com/ ) - Yahoo Technologie
- AOL (http://search.aol.com/aolcom/ ) - Google Technologie
- Fireball (http://www.fireball.de/ ) - Deutschsprachige Suchmaschine
- Google (http://www.google.de/ ) - Zur Zeit der größte Index
- Lycos (http://www.lycos.de/ ) - Yahoo Technologie
- MSN (http://search.msn.com/ ) - Microsofts eigene Suchmaschine
- Search.ch (http://www.search.ch/) - Schweizer Suchmaschine
- Yahoo! (http://www.yahoo.de) - Yahoo Technologie
Suchmaschinen für die eigene Website (Auswahl)
- Atomz (http://www.atomz.com/ )
- Crawl-It (http://www.crawl-it.de/ )
- SJN (http://www.sjn.de/ )
- W3 SiteSearch (http://www.w3sitesearch.com/ )
Wichtige Metasuchmaschinen
- Excite (http://www.excite.com/ )
- MetaGer (http://www.metager.de/ )
- Metaspinner (http://www.metaspinner.de/ )
- WebCrawler (http://www.webcrawler.com/ )
Weblinks
- Die Suchfibel - Alles über die Websuche
- http://www.kso.co.uk/de/tools.html - Suchmaschinentools
- Einführung, Tests, Übungen und weiteres Lehr- und Lernmaterial
- Suchmaschine für Suchmaschinen
- SuchmaschinenWiki - Sozusagen ein Wikipedia für Suchmaschinen
- http://suchmaschinen-web.de/ Und noch ein SuchmaschinenWiki
- - Suchmaschinen – An der Grenze von Optimierung und Spam (Facharbeit 15 Pkt)
- Freiwille Selbstkontrolle Multimedia-Diensteanbieter
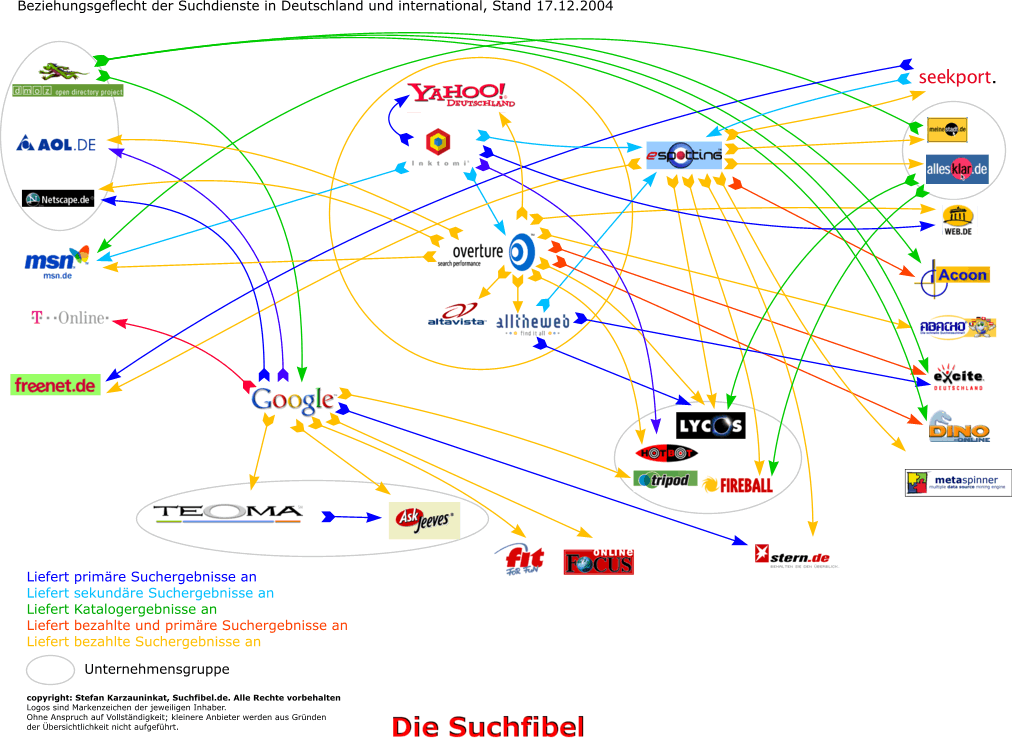
- Beziehung der Suchmaschinen zueinander
{kind=link}